Big Data, Brewer, And A Couple Of Webinars
Whenever I think about big data, I can't help but think of beer – I have Dr. Eric Brewer to thank for that. Let me explain.
I've been doing a lot of big data inquiries and advisory consulting recently. For the most part, folks are just trying to figure out what it is. As I said in a previous post, the name is a misnomer – it is not just about big volume. In my upcoming report for CIOs, Expand Your Digital Horizon With Big Data, Boris Evelson and I present a definition of big data:
Big data: techniques and technologies that make handling data at extreme scale economical.
You may be less than impressed with the overly simplistic definition, but there is more than meets the eye. In the figure, Boris and I illustrate the four V's of extreme scale:
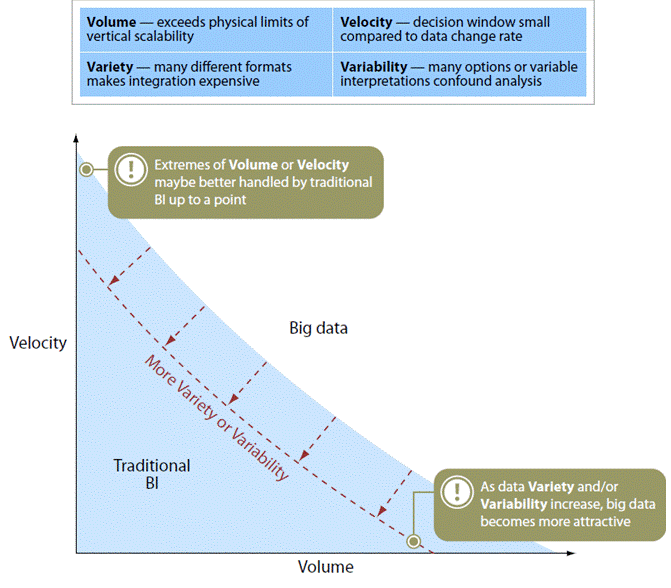
The point of this graphic is that if you just have high volume or velocity, then big data may not be appropriate. As characteristics accumulate, however, big data becomes attractive by way of cost. The two main drivers are volume and velocity, while variety and variability shift the curve. In other words, extreme scale is more economical, and more economical means more people do it, leading to more solutions, etc.
So what does this have to do with beer? I've given my four V's spiel to lots of people, but a few aren't satisfied, so I've been resorting to the CAP Theorem, which Dr. Brewer presented at conference back in 2000. I'll let you read the link for the details, but the theorem (proven by MIT) goes something like this:
For highly scalable distributed systems, you can only have two of following: 1) consistency, 2) high availability, and 3) partition tolerance. C-A-P.
Translating the nerd-speak, as systems scale, you eventually need to go distributed and parallel, which requires tradeoffs. If you want perfect availability and consistency, system components must never fail (partition). If you want to scale using commodity hardware that does occasionally fail, you have to give up having perfect data consistency. How does this explain big data? Big data solutions tend to trade off consistency for the other two – this doesn’t mean they are never consistent, but the consistency takes time to replicate through big data solutions. This makes typical data warehouse appliances, even if they are petascale and parallel, NOT big data solutions. Make sense?
What are big data solutions? We are giving some webinars on the topic to help you get answers:
- Expand Your Digital Horizons With Big Data on September 7, from 11-12 p.m. Eastern time. I will co-present in this complementary webinar with Boris Evelson. Non-Forrester clients can go to the link and register.
- Getting A Handle On Big Data – Is It A Big Deal? on September 12, from 1-2 p.m. Eastern time. This is for enterprise architecture professionals who are Forrester Clients.
These will feature material from my recent research, Expand Your Digital Horizon With Big Data, as well as from Big Opportunities In Big Data and many recent inquiries.
Hope to speak with you there. Now, thanks, Dr. B…I need a brew.
Categories
